Microsoft’s recommendations for performance optimizations are interesting:
- Calls between tiers (client/server) are slow.
- Method calls are expensive. Try to reduce the number of calls. For example, don’t call the same method several times if you can store a value from the method and instead use that value.
These statements are probably true but as with all good advice it is important to know the context in which it makes sense. How slow is slow and how expensive is expensive? And should you worry about it? Let’s find out.
Test cases
In X++ there are different kinds of methods and different ways to call them. There are some interesting cases I can think of right away.
- Static versus instance methods
- Staying on the same tier versus calling methods across tiers
- Calling a method on an object of a supertype (Object) instead of the exact subtype
- Calling a method through reflection (SysDict* classes)
Test setup
Methods calls may be slow, but they’re certainly not slow enough to accurately measure the time of a single call. Repeating the exact same call a large number of times should average out any measurement errors.
The timing code is basically this:
timer.start(1);
for (i=1; i<=maxLoop; ++i)
{
// method call here
}
timer.stop(1); |
timer.start(1);
for (i=1; i<=maxLoop; ++i)
{
// method call here
}
timer.stop(1);
Note that the loop overhead will be included in the measurement as well. This is not really a problem because we will use the same setup for all test cases, replacing the loop body. We’re not interested in exactly how long it takes to call a method, only in performance of the cases relative to each other. Absolute execution times depend on the configuration of the system while relative differences don’t change much between different setups. It’s a bit crude but I think it will suffice.
MaxLoop is set at 100,000 and all cases are executed sequentially. To further minimize the effect of other random system activity, all tests are repeated 20 times. This means every method call is executed 2 million times. This should give a pretty good indication of relative performance.
Overhead, e.g. for constructing object, is placed outside the timer statements. All methods are empty, take no input and return nothing. That means there’s nothing but the call going on. I’m assuming that the compiler will not perform any optimizations, like inlining functions. If it does, we should see weird results.
If you want to try this yourself get the full source here (4.0 SP2).
The results
After running the test I got these results.
| # | Case | Avg. time (ms) for 100,000 calls |
| 1 | No method (empty loop) | 481 |
| 2 | Instance method client | 2,347 |
| 3 | Instance method server | 14,809 |
| 4 | Static method client | 2,298 |
| 5 | Static method server | 14,825 |
| 6 | SysDictClass | 3,095 |
| 7 | Call on Object on client | 2,367 |
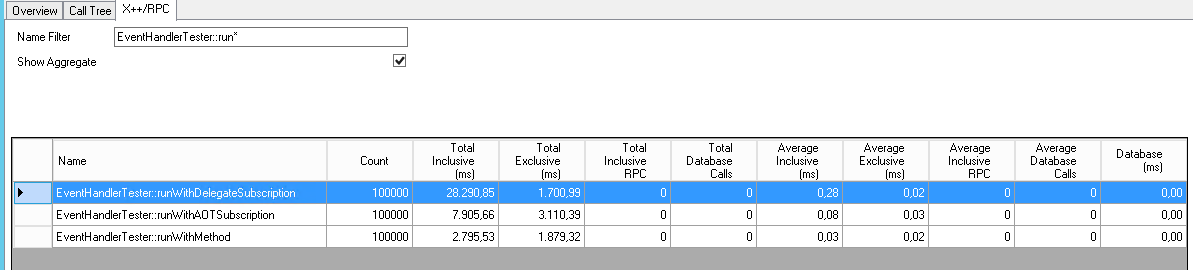
As expected they confirm the Best Practice recommendations. Calling a method on the same tier in a loop is about 3 times slower than an empty loop. It doesn’t really matter if it’s an instance or static method, or if the variable is of the generic Object type. The values are too close together to be statistically significant.
SysDictClass is a bit slower. That makes sense because it uses 2 methods: callObject() on SysDictClass and the method on the object itself. Surprisingly it is a lot faster than twice the value of calling an object method on the same tier. It is closer to a combination of no method and a method call on the same tier. If I had to guess I would say it is because callObject() is a method in the kernel, written in C/C++ instead of X++. Maybe there is less overhead in dealing with kernel functions. Too bad we can’t include an empty kernel method in the test to verify this.
Finally, this proves methods calls across tiers are slow. Extremely slow compared to anything else. In this setup crossing a tier is about 6 to 7 times slower than staying on the same tier. Keep in mind that these methods do not take any input and return nothing. Also, the AOS and client are on the same machine. In real code with parameters, return types and network latency it will be worse.
Conclusion
The optimization guidelines are correct. Now should you worry about it and avoid methods? Generally not. Breaking up code in methods improves readability of the code. Adding too many temporary variables to avoid calling the same method again can become annoying too. Usually a programmer’s time is more important (and more expensive) than execution time. It’s not worth it to optimize everything.
If you stay on the same tier you can do a lot of method calls per second. Unlike this test setup, real methods have code that takes time to execute as well The time spent performing the actual method call will be insignificant in most situations. Readability and clean design trumps performance. If X++ would support some function inlining we could have the best of both worlds with minimal effort.
When crossing from client to server or vice versa, things are more complicated. As the results show this causes a significant performance hit. From the start your code should be designed to minimize traffic between tiers. A single call won’t hurt but often bad code contains a lot of subsequent calls to objects that live on the other tier, like when constructing an object and setting it up with accessor methods. In these cases it’s better to use containers and provide methods to pass all data in a single call. Simple client/server optimizations can make a huge difference. Improvements in this area are something users could actually notice themselves.