Lately I’ve been involved quite a bit in performance analysis and tuning on Ax 2012. It’s not only important to solve the customer’s requirements but at the same time the solution must be implemented in a way that its processing ends before the heath death of the universe.
There’s are lot to say about performance but for now I’ll just stick to a quick heads-up about event handlers and delegates. And to boot I can demonstrate it without worrying about customer specific information.
Eventing was added to Ax 2012 but it’s not widely used in the standard code (if at all). Despite the potentially cleaner design, I’ve seen some instances where it caused some issues.
I decided to try to measure the overhead caused by eventing, ignoring whatever business logic they might perform. The results were beyond my expectations.
My test setup is a simple class with empty methods for different scenarios. The test was performed on an Ax 2012 R3 demo VM.
On the method runWithAOTSubscription a post event handler is defined that calls theAOTHandler. Method runWithDelegateSubscription calls theDelegate to which theDelegateMethod is subscribed using the eventHandler function. Lastly, runWithMethod directly calls theMethod without any events in between.
In main() every scenario is executed 100000 times.
public static void main(Args _args)
{
EventHandlerTester eht = new EventHandlerTester();
int i;
int maxLoops = 100000;
;
for(i=1; i<=maxLoops; i++)
{
eht.runWithAOTSubscription();
}
eht.theDelegate += eventhandler(EventHandlerTester::theDelegateMethod);
for(i=1; i<=maxLoops; i++)
{
eht.runWithDelegateSubscription();
}
for(i=1; i<=maxLoops; i++)
{
eht.runWithMethod();
}
} |
public static void main(Args _args)
{
EventHandlerTester eht = new EventHandlerTester();
int i;
int maxLoops = 100000;
;
for(i=1; i<=maxLoops; i++)
{
eht.runWithAOTSubscription();
}
eht.theDelegate += eventhandler(EventHandlerTester::theDelegateMethod);
for(i=1; i<=maxLoops; i++)
{
eht.runWithDelegateSubscription();
}
for(i=1; i<=maxLoops; i++)
{
eht.runWithMethod();
}
}
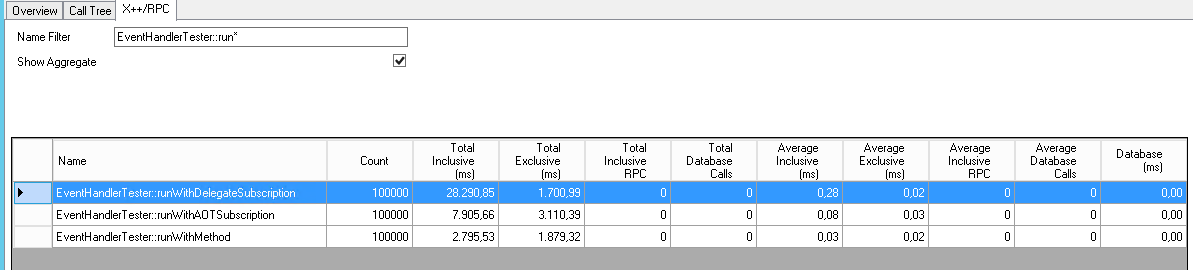
Using the trace parser I found some interesting results. I ran it a couple of times and results were consistent.
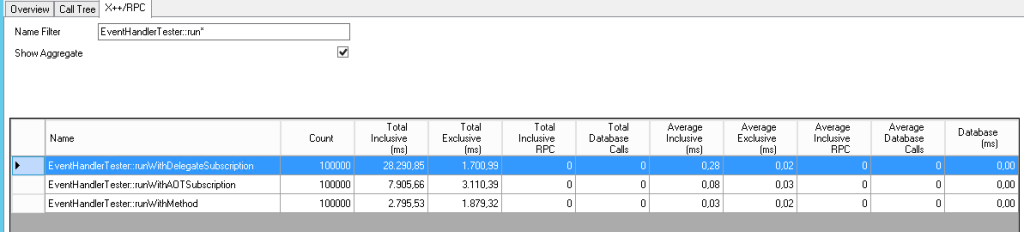
The event handlers subscribed using eventHandler are by far the worst. When looking at the call tree it’s fairly obvious why: there seems to be a lot of bookkeeping going on internally.

Event handlers defined in the AOT are an improvement, even though it’s the only scenario which uses a parameter (XppPrePostArgs). This could make matters worse but actually it doesn’t.
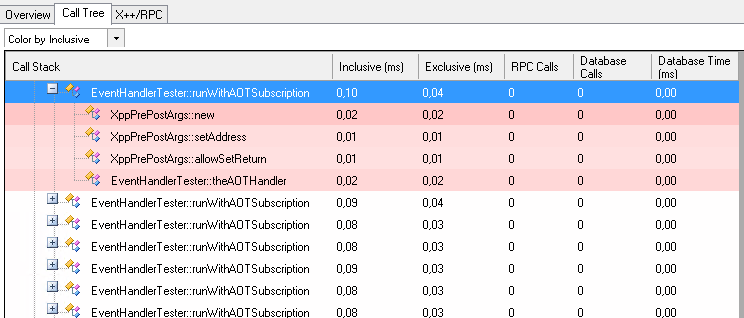
And as expected it’s still quicker when calling a method directly.
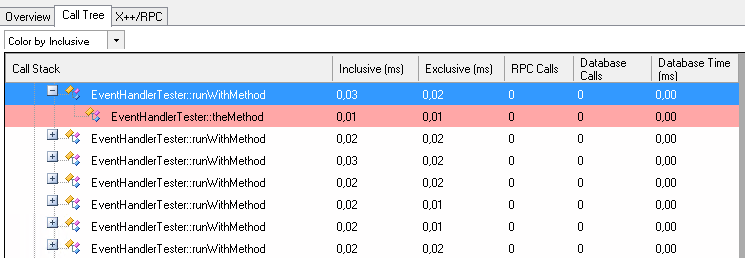
Now why did I bother investigating this? Because I’ve seen the effect of using event handlers on data methods of often used tables. Even ignoring the body of the event handlers, the simple fact of calling the event handler has a noticeable performance cost. I’m not advocating against the use of event handlers but beware of them when they’re part of code involved in a performance problem.
If you’d like to test this yourself you can use the XPO. Let me know if you have other results or if my approach is flawed (it was getting late when I came up with the idea :)).