There’s a problem when modifying marked transactions. It’s possible to end up with a transaction that is not reserved but has a reference lot ID anyway, i.e. is marked to another transaction. This can lead to hard to explain problems down the line, e.g. after running the master planning planned orders are missing or incorrectly matched to outgoing transactions.
Scenario
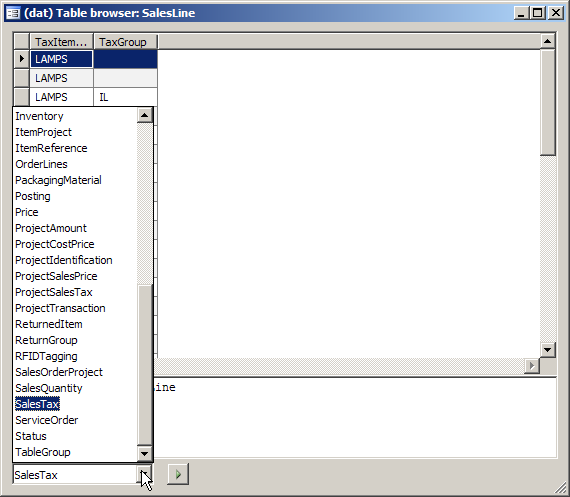
There is an easy way to trigger this. Create a sales order for an item. Then create a linked purchase order for the amount sold. This marks both inventory transactions to each other. The inventory transaction for the sales line issue is in status reserved ordered and contains the reference lot ID of the purchase order line.
Now increase the quantity on the sales line. This creates a second inventory transaction for the new quantity in issue status on order and with the same reference lot ID. This means the new quantity is also marked to the same purchase order. This is obviously not correct.
Marking implies reserved transactions (physically or ordered) and the quantities on both sides should match. In this case the purchase order is not sufficient for the quantity sold. That’s why the new transaction is put in status on order in the first place. Unfortunately the marking is not fixed.
Something similar happens when you increase the purchase quantity instead of the sales quantity.
Fix
This behavior is fixed in Dynamics Ax 4.0 SP1. And the good news is it can be backported. The bug resides in InventUpd_Estimated.createEstimatedInventTrans(). This is where a new InventTrans record is created for the added quantity. It correctly determines the issue status and then stops. In 4.0 the marking is checked there as well.
The end of the method looks like this:
if (movement_Orig) inventTrans.updateSumUp(); updEstimated += qty; |
Replace it with this:
updEstimated += qty; // Fix 4.0 SP1 >> if (movement.inventRefTransId()) // Marking for entire lotId exists => additional should also be marked { markNow = InventTrans::updateMarking(movement.inventRefTransId(), movement.transId(), -qty, '', SortOrder::Descending); if (markNow) { if(abs(markNow) 0 ? abs(markNow) : - abs(markNow)); inventTrans.InventRefTransId = movement.inventRefTransId(); inventTrans.update(); InventTrans::findTransId(inventTrans.InventRefTransId, true).updateSumUp(); } if (qty < 0) // issue { InventUpd_Reservation::updateReserveRefTransId(movement); // try to make reservation according to marking - } else { inventTransMovement = InventTrans::findTransId(movement.inventRefTransId()); if(inventTransMovement) { movementIssue = inventTransMovement.inventMovement(true); // no Throw if not initiated if(movementIssue) InventUpd_Reservation::updateReserveRefTransId(movementIssue); // try to make reservation according to marking - } } if (!markNow && inventTrans.InventRefTransId) // reset InventRefTransId if no marking could be made { inventTrans.InventRefTransId = ''; inventTrans.update(); } } // << if (movement_Orig) inventTrans.updateSumUp(); |
You’ll also need to add these variables at the top:
InventQty markNow; InventMovement movementIssue; InventTrans inventTransMovement; |
Final remarks
I could reproduce this on a standard 3.0 SP5 installation. I was a bit surprised to see that this has gone unnoticed for so long. However it is a subtle bug that is hard to spot. The transaction status is correct and the effects of marking aren’t immediately visible.
This kind of inconsistency can really mess up the InventTrans table. Without the fix try, increasing the purchase quantity and then on the sales order remove the inventory marking completely. You end up with several inventory transactions for the purchase order. Some of which are still marked to the sales order.